MovieFlix
Business Requirements MovieFlix allows users to watch TV shows and movies on demand. They want the following capabilities:
- Allow users to resume videos where they left off.
- Build a user profile in real time.
- Recommend the next show to the user in real time.
- Store all data in an analytics store.
Kafka Implementation
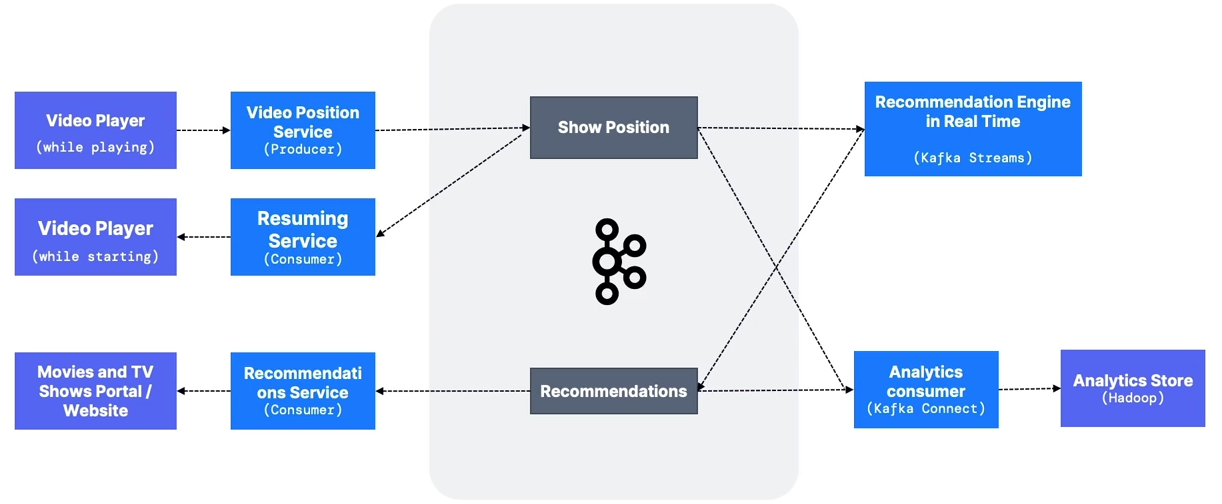
show_positiontopic- Can have multiple producers.
- Should be highly distributed if high volume (> 30 partitions).
- Suggested key:
user_id.
recommendationstopic- The Kafka Streams recommendation engine may source data from the analytics store for historical training.
- May be a low-volume topic.
- Suggested key:
user_id.
GetTaxi
Business Requirements GetTaxi matches riders with taxi drivers on demand. They want the following capabilities:
- Match the user with a nearby driver.
- Implement surge pricing when driver availability is low or user demand is high.
- Store all position data before and during rides in an analytics store for accurate cost computation.
Kafka Implementation
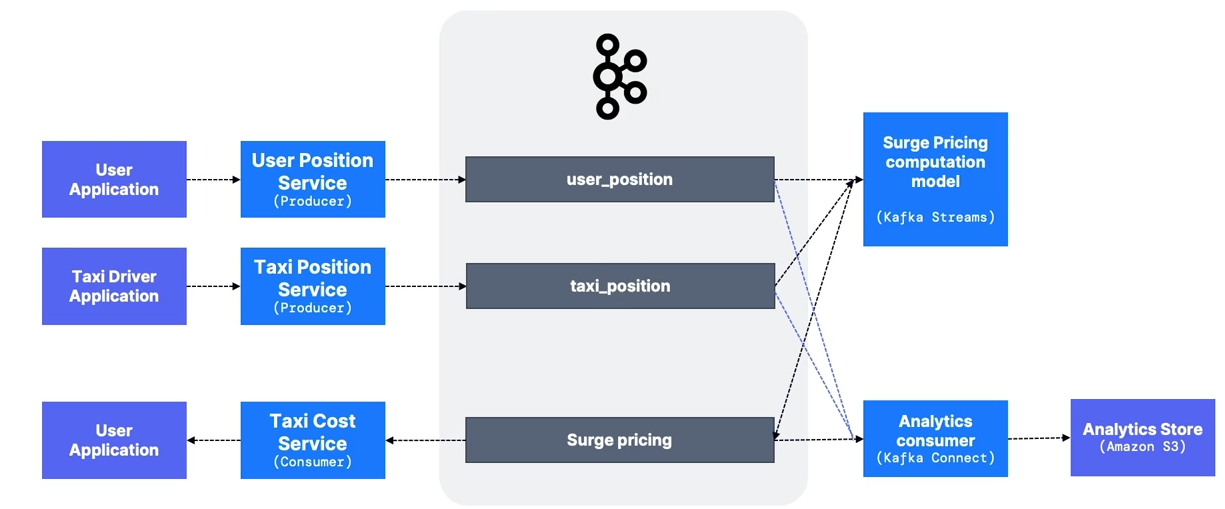
-
taxi_position,user_positiontopics- Multiple producers.
- Highly distributed if high volume (> 30 partitions).
- Suggested keys:
user_id,taxi_id. - Data is ephemeral and likely does not require long retention.
-
surge_pricingtopic- Computed by a Kafka Streams application.
- Surge pricing may be regional, making this topic high volume.
- Other influencing topics such as
weatheroreventscan be included in the Kafka Streams application.
MySocialMedia
Business Requirements MySocialMedia allows users to post images, like, and comment. They want the following capabilities:
- Users can post, like, and comment.
- Show total likes and comments per post in real time.
- Handle high data volume at launch.
- Display trending posts.
Kafka Implementation
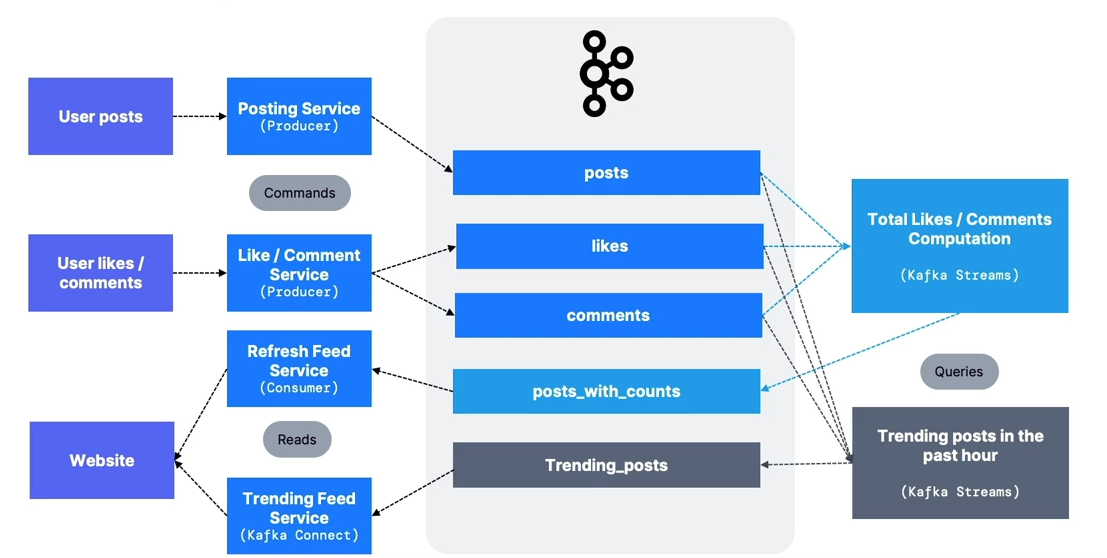 The architecture follows CQRS (Command Query Responsibility Segregation).
The architecture follows CQRS (Command Query Responsibility Segregation).
poststopic- Multiple producers.
- Highly distributed if high volume (> 30 partitions).
- Suggested key:
user_id. - High data retention period.
likes,commentstopics- Multiple producers.
- Highly distributed (expected to be very high volume).
- Suggested key:
post_id.
- Event formatting examples:
User_123 created post_id 456 at 2pmUser_234 liked post_id 456 at 3pmUser_123 deleted post_id 456 at 6pm
MyBank
Business Requirements MyBank provides real-time banking and wants to add a feature that alerts users of large transactions.
- Transaction data exists in a database.
- Users can define thresholds.
- Alerts must be sent in real time.
Kafka Implementation
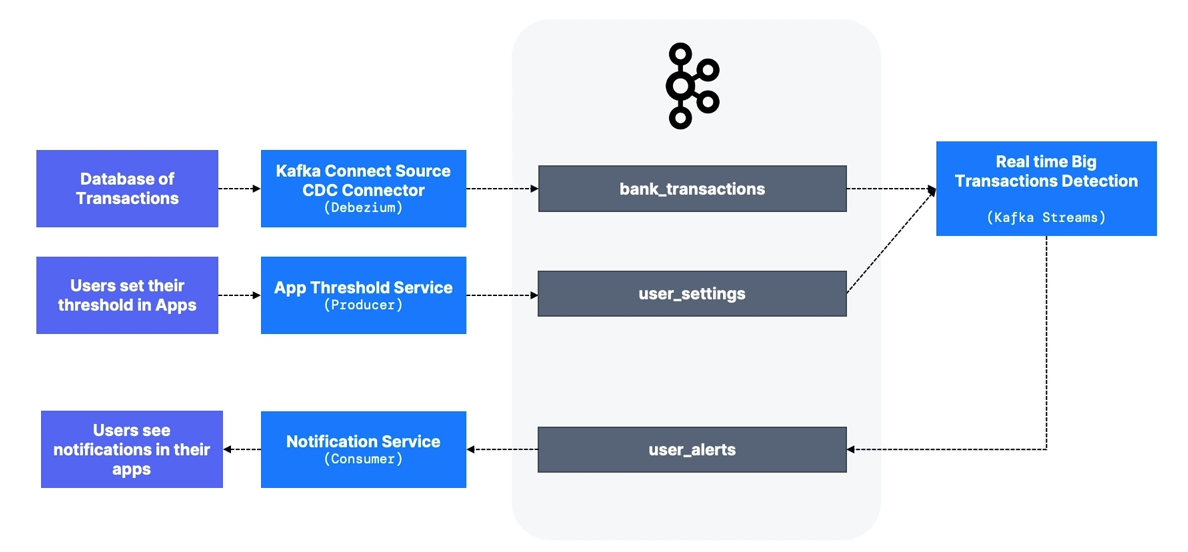
bank_transactionstopic- Use Kafka Connect Source to expose data from existing databases.
- Many CDC connectors are available (PostgreSQL, Oracle, MySQL, SQL Server, MongoDB, etc.).
- Kafka Streams application
- User threshold changes do not trigger alerts for past transactions.
user_thresholdstopic- Prefer event-based messages (e.g.,
User_123 enabled threshold $1000 at 12pm on July 12, 2018) instead of state-based messages (User_123: threshold $1000).
- Prefer event-based messages (e.g.,
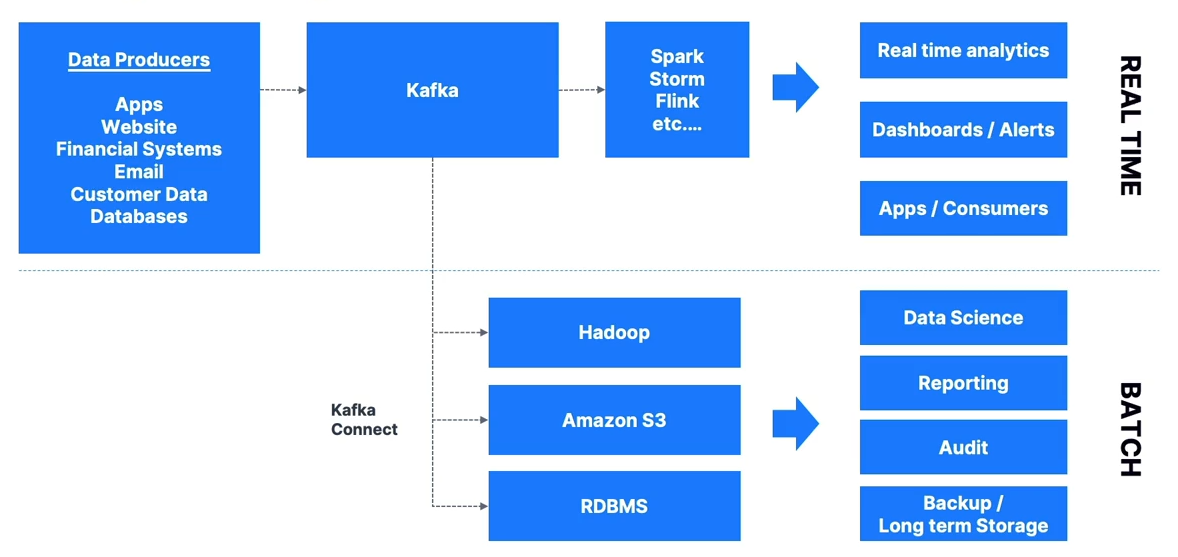
Big Data Ingestion
- Common to use connectors to offload data from Kafka to HDFS, Amazon S3, Elasticsearch, etc.
- Kafka often serves as a speed layer for real-time apps, paired with a slow layer for later analytics.
- Kafka is frequently used as an ingestion buffer in front of big data stores.
Logging and Metrics Aggregation
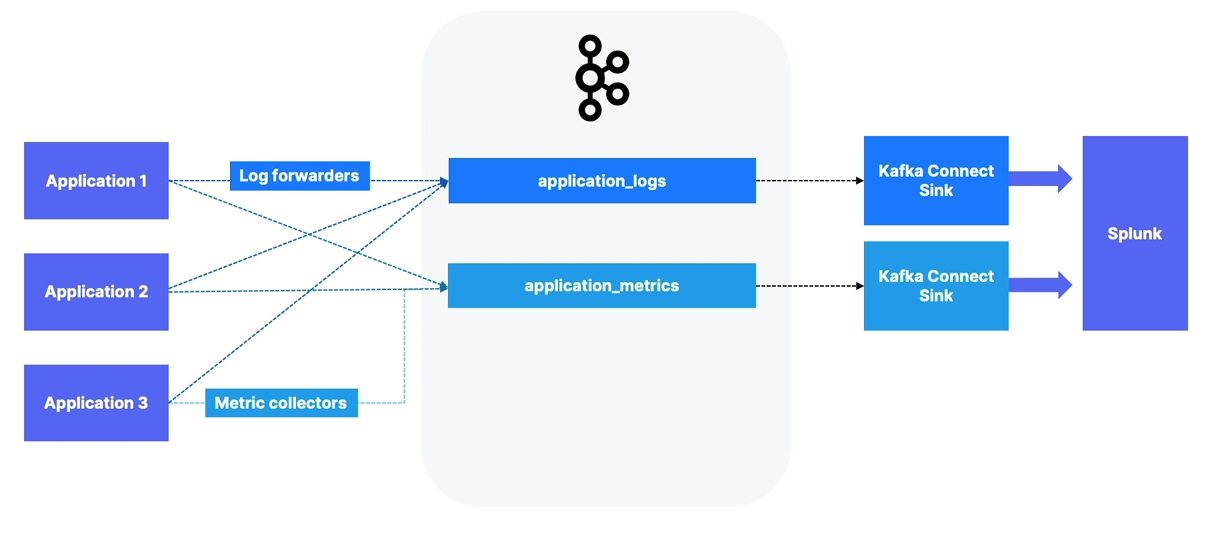
- One of Kafka’s earliest use cases was ingesting logs and metrics from multiple applications.
- Typically requires high throughput and has fewer constraints around data loss or replication.
- Application logs can be sent to tools like Splunk, CloudWatch, or ELK.