Overview
- A Kafka cluster is composed of multiple brokers (servers)
- Each broker is identified by a unique integer ID
- Each broker stores specific topic partitions
- Connecting to any broker (called a bootstrap broker) allows access to the entire cluster
- Kafka clients automatically discover all brokers using metadata
- A typical starting point: 3 brokers
- Large clusters may have 100+ brokers
- In examples, brokers are numbered starting from 100 (arbitrary choice)
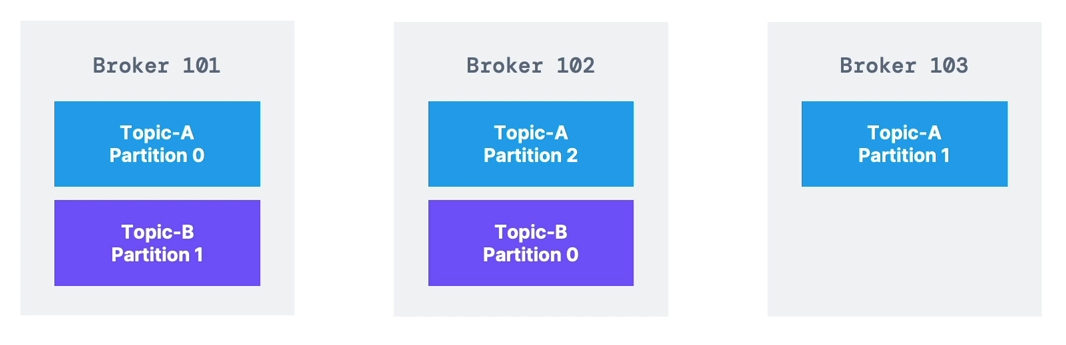
Example: Topic Distribution
- Topic-A: 3 partitions
- Topic-B: 2 partitions
- Data is distributed across brokers; some brokers may have no data for a topic
- Example: Broker 103 has no Topic-B data
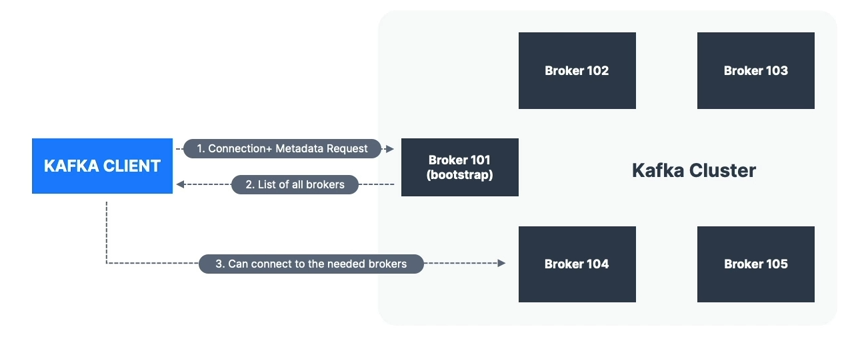
Kafka Broker Discovery
- Every broker is also called a bootstrap server
- You only need to connect to one broker — the client will discover the rest
- Each broker stores metadata about:
- All brokers
- All topics
- All partitions
Replication Factor
- Topics should have replication factor > 1 (commonly 2 or 3)
- This ensures high availability — if one broker goes down, others can serve the data
- Example:
- Topic-A has 2 partitions
- Replication factor = 2
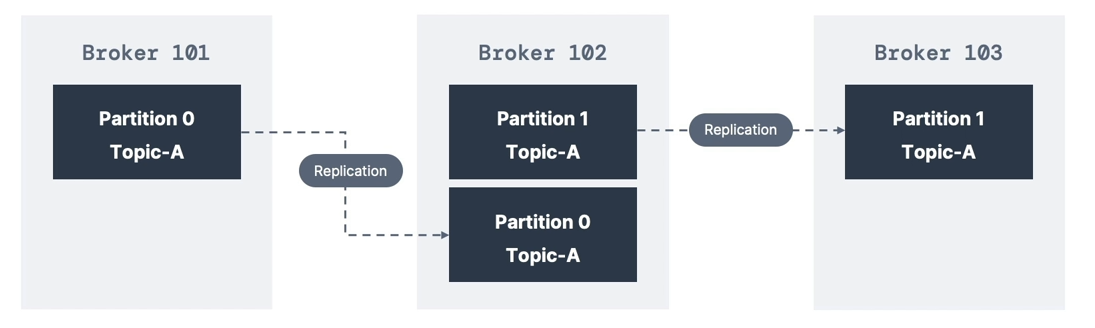
- Example: Losing Broker 102
- Brokers 101 and 103 still serve all data
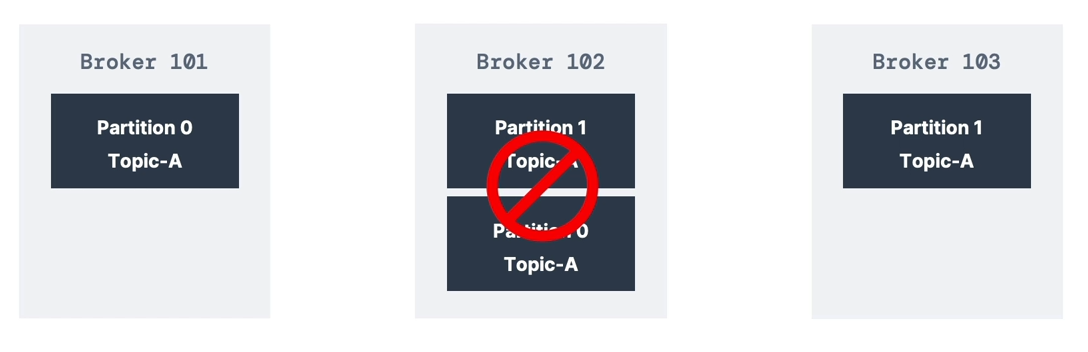
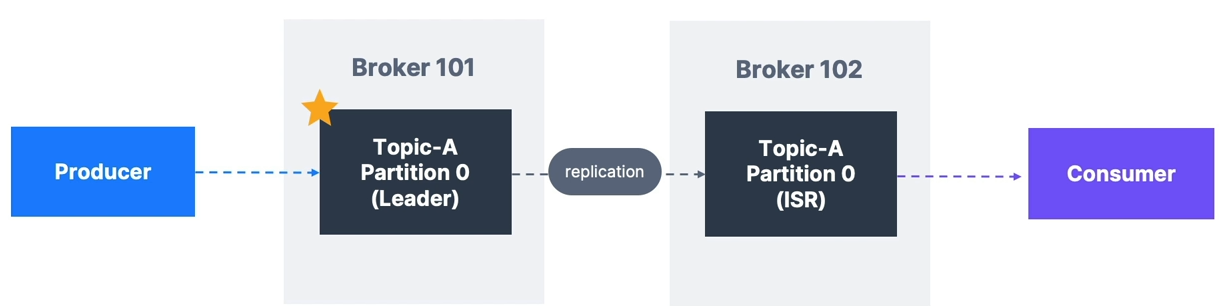
Partition Leaders
- Only one broker can be the leader for a partition at a time
- Producers send data only to the leader broker of a partition
- Other brokers store replicas of the data (called ISR — In-Sync Replicas)
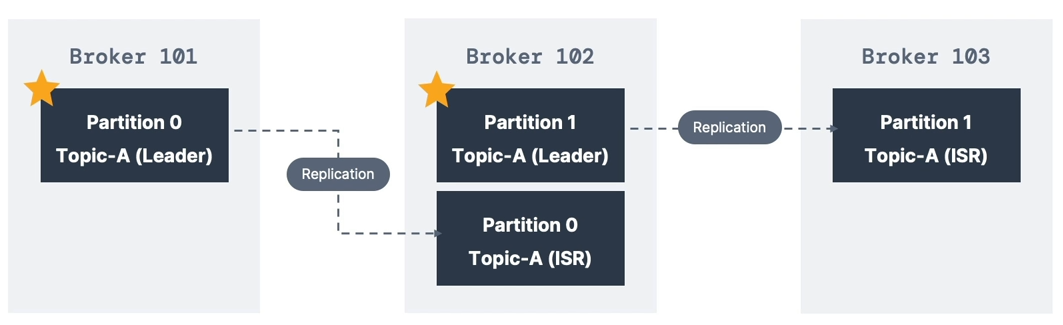
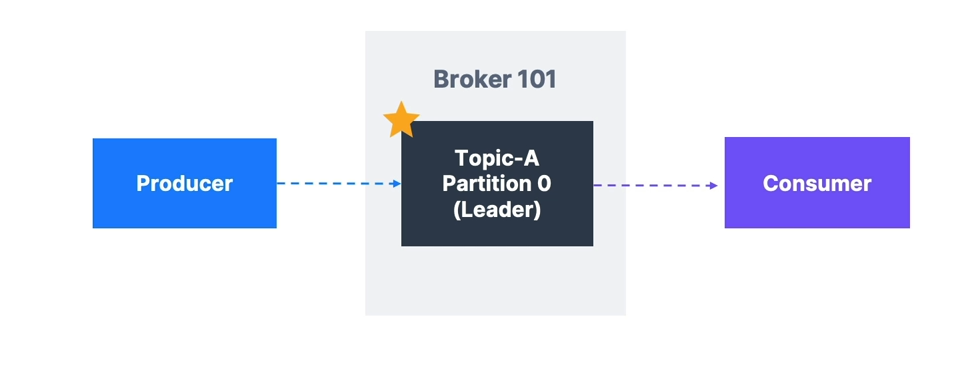
- Producers write only to the leader broker
- Consumers by default read from the leader broker
Reading from Closest Replica (Since Kafka 2.4)
- Consumers can be configured to read from the closest replica instead of the leader
- Benefits:
- Reduced latency
- Lower network costs (especially in cloud deployments)