☕ Mansour’s Kafka Notes
It looks like you’ve pasted a set of talking points or notes that outline the challenges of point-to-point integrations and why Apache Kafka is a good alternative for scalable, decoupled data movement.
Here’s a clean, structured rewrite that could be used for a presentation or documentation:
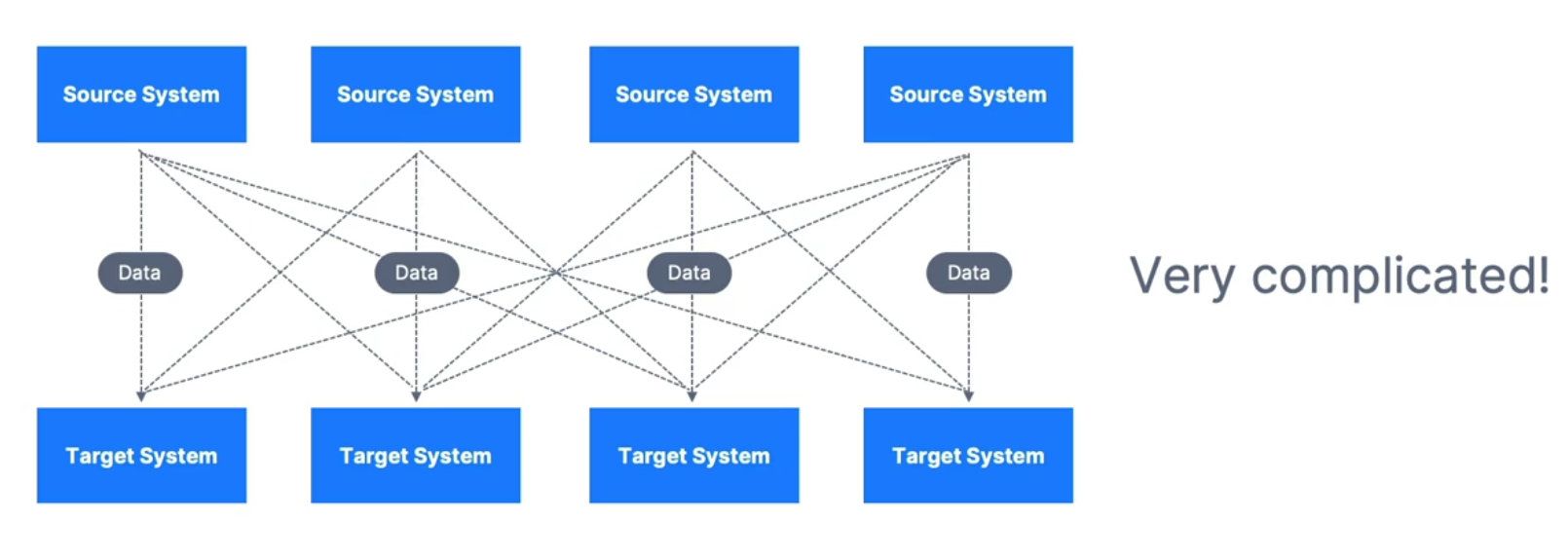
The Problem: Point-to-Point Integrations
-
Example: 4 source systems and 6 target systems → 24 integrations to write and maintain.
-
Challenges with each integration:
-
Protocol: How the data is transported (TCP, HTTP, REST, FTP, JDBC, …)
-
Data format: How the data is parsed (Binary, CSV, JSON, Avro, Protobuf, …)
-
Data schema & evolution: How the data is shaped and how it changes over time
-
System load: Each source system experiences increased load from multiple direct connections
-
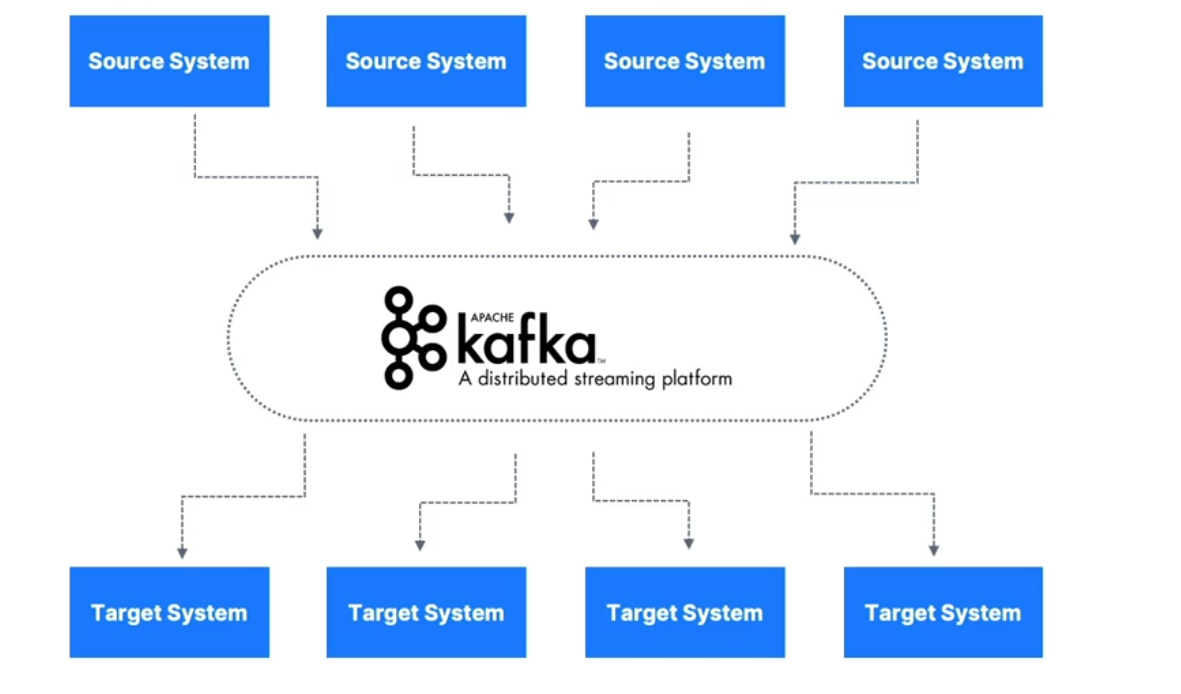
Apache Kafka Overview
-
Origin: Created by LinkedIn, now an open-source project
-
Maintained by: Confluent, IBM, Cloudera, and the community
-
Key Features:
-
Distributed, resilient, fault-tolerant architecture
-
Horizontal scalability (scale to 100s of brokers)
-
Handles millions of messages per second
-
Low latency (<10ms) → suitable for real-time applications
-
-
Adoption: Used by 2000+ firms, including 80% of the Fortune 100
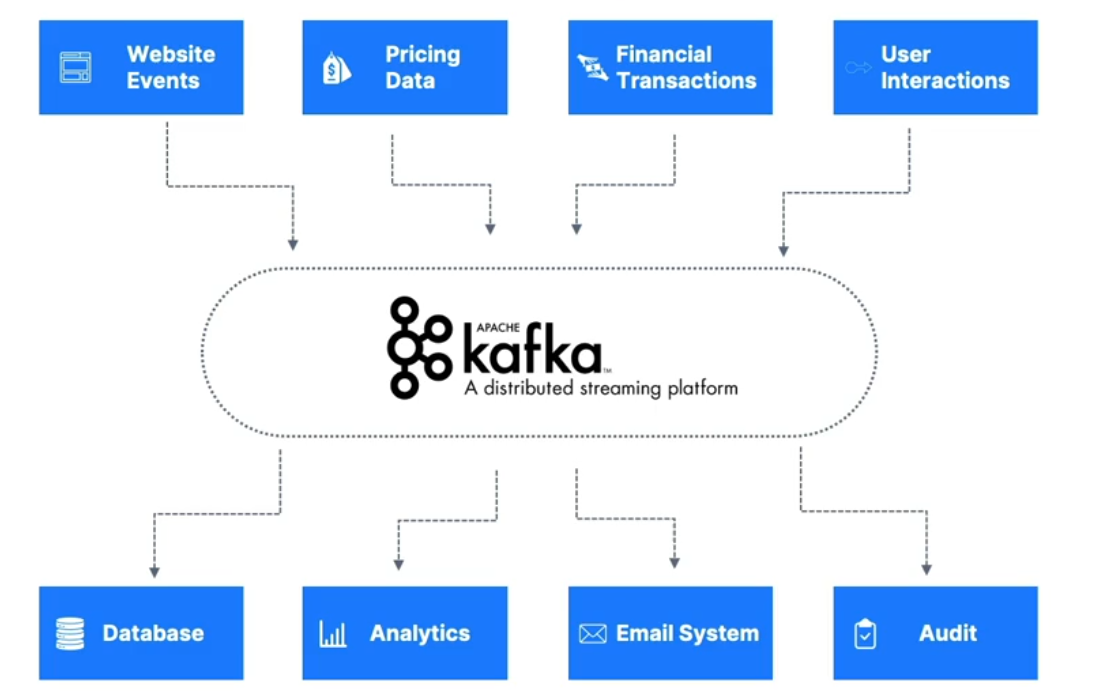
Apache Kafka Use Cases
-
Messaging system
-
Activity tracking
-
Collecting metrics from many locations
-
Aggregating application logs
-
Real-time stream processing (e.g., Kafka Streams API)
-
Decoupling system dependencies
-
Integration with big data tools: Spark, Flink, Storm, Hadoop, etc.
-
Pub/Sub for microservices
Real-World Examples
-
Netflix: Real-time recommendations while you watch
-
Uber: Real-time trip data for demand prediction & surge pricing
-
LinkedIn: Real-time spam prevention and connection recommendations
-
Important: Kafka is a transportation mechanism, not a processing engine
If you want, I can also turn this into a clear diagram showing the “before and after” of point-to-point integrations vs. Kafka’s pub/sub model — that would make it visually click for stakeholders. That diagram could include the 4 source → 6 target example to emphasize the N×M integrations problem.
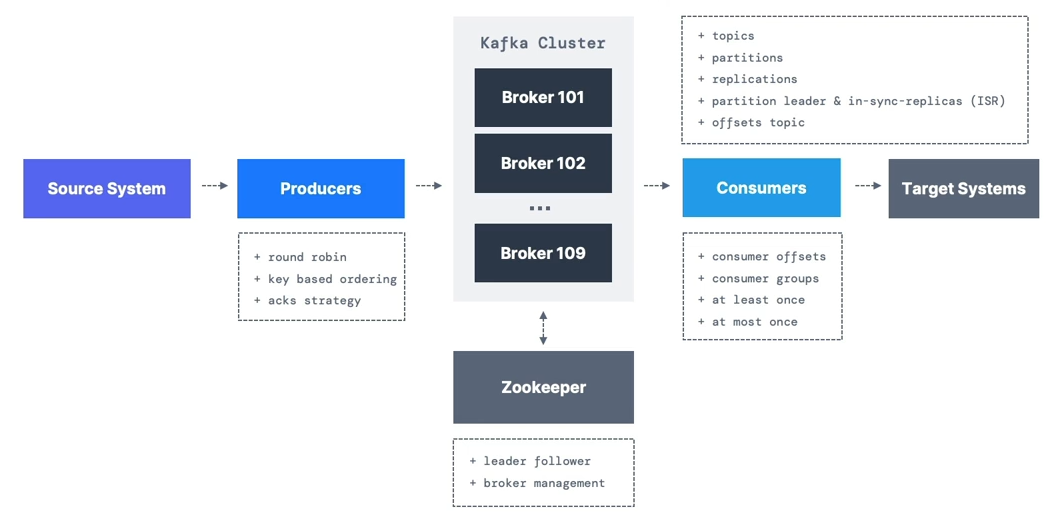
Delivery Semantics
At Most Once
- Offsets are committed as soon as the message batch is received.
If the processing goes wrong, the message will be lost (it won’t be read again).
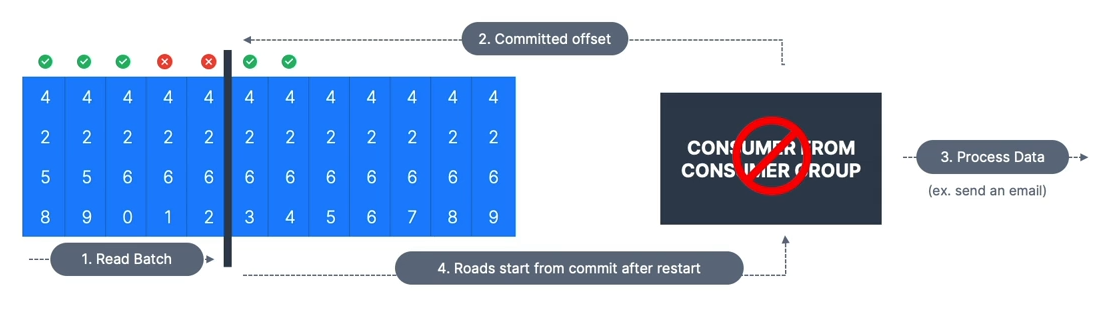
At Least Once (Preferred)
- Offsets are committed after the message is processed.
If the processing goes wrong, the message will be read again.
This can result in duplicate processing of messages — make sure your processing is idempotent (processing again won’t impact your systems).

Exactly Once
-
Can be achieved for Kafka workflows using the Transactional API (easy with Kafka Streams API).
-
For Kafka Sink workflows, use an idempotent consumer.
Bottom line: For most applications, you should use at least once processing and ensure your transformations/processing are idempotent.